音色设计
用自然语言定义性别、年龄、质感、情绪和语速,快速形成可用于品牌、角色或内容栏目的专属声音方向。
用自然语言定义性别、年龄、质感、情绪和语速,快速形成可用于品牌、角色或内容栏目的专属声音方向。
基于参考音频复现说话人音色,并通过风格指令控制情绪、节奏与表达强度,适配更真实的业务语境。
在有授权素材的前提下保留音色、节奏、情绪和细节表达,适合高一致性的角色语音和内容资产生产。
可围绕业务后台、内容平台或内部工具封装调用链路,让语音生成进入真实的生产、审核和发布流程。
覆盖普通话、中文方言和多语种内容,适合跨区域内容生产、出海本地化和多市场运营。
围绕样本文案、目标音色、使用规模、权限边界和交付方式,形成更可落地的售前判断。
面向多语言内容、本地化运营和区域市场表达,支持多语种与中文方言能力,让同一套声音系统服务更广泛的受众。
四川话、粤语、吴语、东北话、河南话、陕西话、山东话、天津话、闽南话。
VoxCPM2 工作在 AudioVAE V2 的连续潜空间中,结合 LocEnc、TSLM、RALM、LocDiT 等模块,把文本理解、韵律规划、音色控制和音频还原整合到统一生成链路。
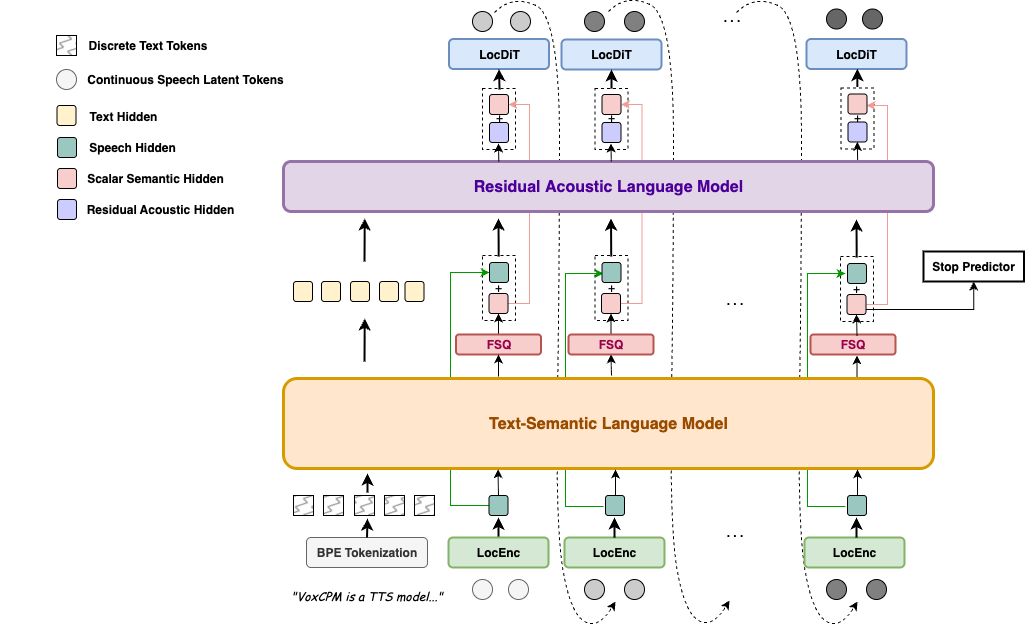
适合内容创作、客服播报、教育课件、短视频配音、有声读物、游戏角色语音和多语言本地化等场景。